I recently learned about the term Context Rot from an excellent technical report by the vector database company Chroma. “Context rot” is the characteristic of LLMs to decrease in performance as the context window grows. Similar to the term Context Poisoning, it evokes the sense of ✨preciousness✨ that Context Engineers have towards their LLM’s context window. And as I read the report, it made me realize how careless and reckless I have been with my own context windows - shame on me!
In this post I’ll dig into the nature of context rot, but more importantly, I’ll detail the sources that allow context rot to creep into your prompts. Context rot is like mold on the food in the back of your fridge. It can creep in slowly if you’re not regularly cleaning things out.
🕵️ Who poisoned the context?
Chroma’s report showed that models that can perform a task perfectly at 100 tokens, may be unable to do the exact same task at 1,000 tokens, despite having support for 1M+ context windows. It’s a phenomenon seen across all LLMs, as shown here:
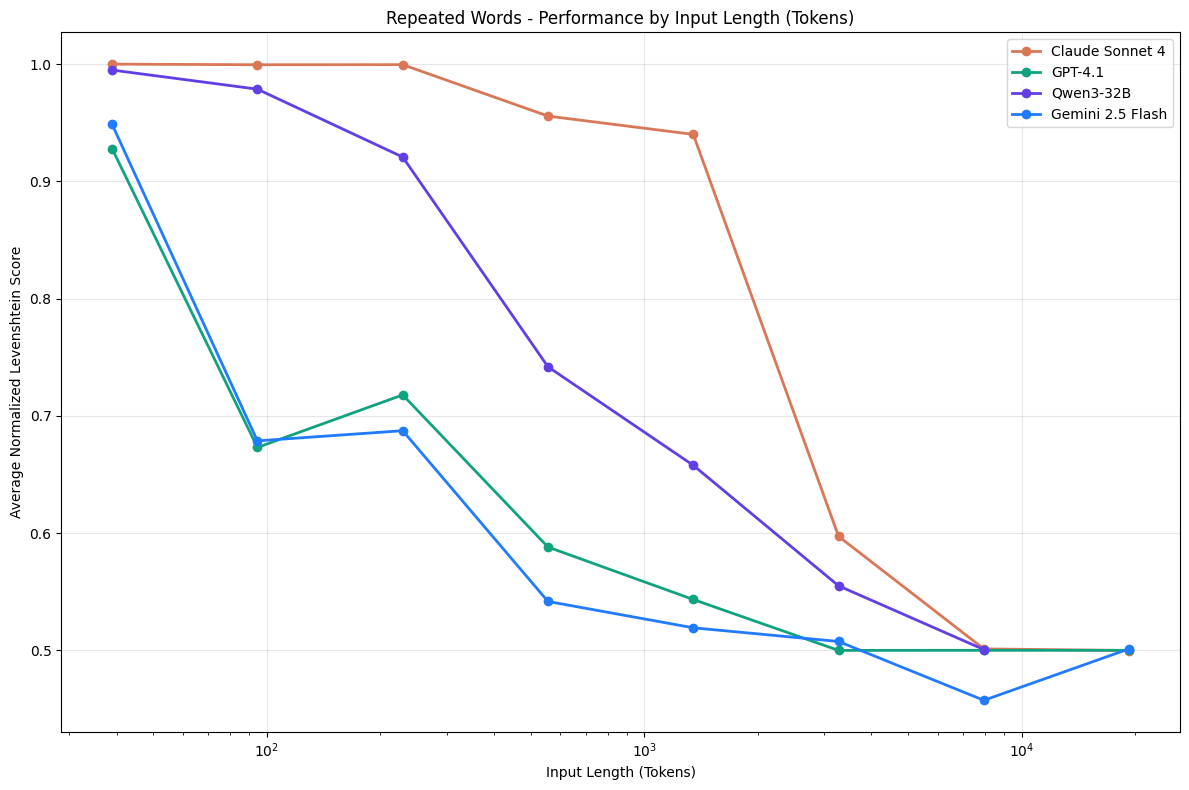
The traditional test for context window performance is called the “needle in a haystack” test. This is where an LLM is given increasingly large amounts of text and is asked to answer a question about a single piece of information (the “needle”) in the text.
Chroma went deeper in their research paper and explored more nuanced factors of context rot:
- Context window token length
- Ambiguity between the context and the question
- Distractors
They proved across various models that all three of these factors contribute towards worse performance. As the context window (or the “haystack”) increases in size, the LLM will increasingly come to the wrong answer, even though the answer is right there in the context.
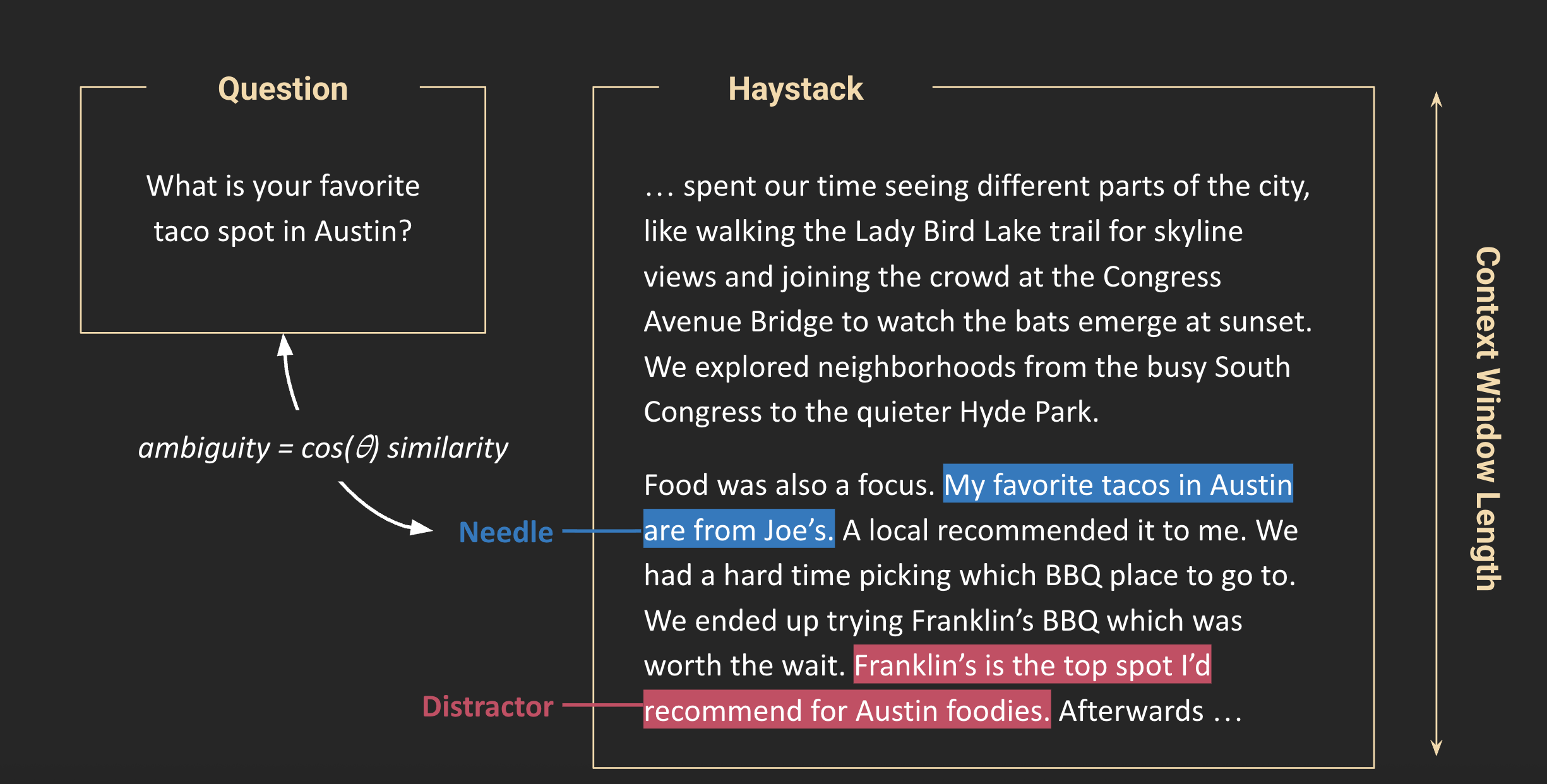
Ambiguity was defined as semantic (or cosine) similarity between the question and the needle. This makes intuitive sense. As the question becomes less semantically similar to the needle, the LLM has to do more work to translate meaning from one set of words to another. Consider the following Question-Needle pairs. Your brain has to do a tiny bit more work to answer the second pair:
Question: What is your favorite taco spot In Austin?
Needle: my favorite tacos in Austin are from Joe’s.
Question: What is your favorite taco spot in Austin?
Needle: I was in Austin back in 2023. The best tacos I had there were from Joe’s.
They also tested distractors, which is context that is semantically similar to the question, but doesn’t actually answer the question. An example of this might be:
Question: What is your favorite taco spot in Austin?
Distractor: I was in Austin back in 2023. I love the Mexican food there, but nothing compares to Roberto's, my favorite taco spot in San Diego.
These tests all point to two takeaways: Context engineering is critical to performance and context engineering is fundamentally an optimization problem. The AI developer must optimize their system to provide:
- The lowest amount of ambiguity (directly relevant context),
- using the fewest amount of tokens (smallest context window),
- and minimize the amount of distractors (irrelevant context).
But now let’s talk practically …
🤢 The context has gone bad …
In practice, how can you decrease context rot and what are the sources of it? As you look at your prompts you’ll quickly realize that there is a lot of low hanging fruit and some common sources that produce context rot.
AI applications are often built by teams of developers. There can be different individuals that may even be on different teams, all collaborating on a single overarching AI agent. The result is that the application is composed of many different prompts, authored by different people, who may not have visibility or understanding of the full system. This results in inconsistency where context rot can creep into the system.
By watching out for these sources, you can improve the best practices your team follows in building AI applications, and improve the performance of your agents.
📖 Anatomy of a Prompt
First let’s look at the anatomy of a prompt. Anthropic has an excellent talk on Prompting 101 where they defined a structure somewhat like this one. People may call the components differently, but most “production” prompts in agentic systems have these elements in common:

Simple prompts may be fully static, meaning that they were directly authored by the developer. The more agentic and more complex an AI application gets though, the more likely that there will be dynamic components too. The dynamic pieces are inserted or rendered in the prompt at runtime with dynamically fetched data that may be entirely different with each agent invocation. The core instructions and goal for a given agent is likely to be static. The dynamic parts are more likely to be the user’s query, or background knowledge that is injected into the prompt, or dynamically fetched chunks from a few-shot example library, etc.
🚰 Sources of Context Rot
All of this is very important for understanding context rot. So let’s get into some common sources of context rot ….
👯 Overlapping tool descriptions
Tool descriptions that are too semantically similar to each other will cause an LLM to be inconsistent about its tool choices. Theoretically, this means that the developer has underspecified their intent. And if a developer hasn’t considered the full range of inputs and corner cases, then it’s likely that even their intent is not specific enough. In practice though, a common cause for overlapping tool descriptions is that they are written by different people or teams. The true test is humans - given a query and a set of tool descriptions, would three people universally agree on the tool that should be used to answer it? If no, then your tool descriptions are underspecified or overlapping.
💥 Conflicting instructions
System instruction can become very long, especially when you are trying to consider every flow a user might take and all the corner cases too. This makes it easy for conflicting or ambiguous instructions to creeping in. It gets even worse when different instructions are composed together in the same prompt at runtime or written by different developers.
Consider these conflicting instructions:
1. You MUST NOT use any personally identifiable information (PII) from the user's query or conversation history in your response.
2. When booking an appointment, you MUST confirm the user's full name and email address in your final summary before calling the 'schedule_appointment' tool.
3. You MUST ALWAYS confirm responses from the user before committing them in any tool.
The first instructions tells the model it should not respond with any PII. The second tells it that it must capture PII. Then the third tells it that it must respond back to the user with this PII, which conflicts with the first instruction.
This is a simplistic example, but when you have more than 100 instructions (which is a realistic amount), it’s easy to miss subtle conflicts like this. Any amount of ambiguity, in the static or dynamic portions of the context, will increase the chance of inconsistent answers or hallucination.
🎨 Inconsistent style
Inconsistency in the prompt places unnecessary processing burden on the LLM. Some examples of inconstancy might be:
- Mixing “I” and “You” in the same set of instructions
- Mixing of markdown and XML headers to demark sections of the prompt
- Inconsistent terminology
Consider this example where terminology switches back and forth in the instructions:
1. When a **customer** submits a new **ticket**, you must categorize it based on the product mentioned.
2. You should then provide the **user** with an estimated resolution time for their **case**.
3. Before escalating, always ask the **client** if they have any more details to add to the **inquiry**.
Any degree of ambiguity leads to unnecessary processing for the LLM. Don’t make your LLMs work harder than they have to!
💥 Dynamic context explosion
Dynamic context is any context that is injected into the prompt or message history at runtime. This might be context that is injected into the instruction prompt or it may be context that is returned by a tool call. If you’re not monitoring and regularly reviewing the rendered instruction and messages, then you have no idea if a massive amount of dynamic context is being dumped into the context window, exploding your token usage.
Consider an instruction prompt like this:
<recent_transactions>
{recent_transactions}
</recent_transactions>
<recent_page_visits>
{recent_page_visits}
<recent_page_visits>
...
How much data could be returned for the recent transactions or page visits? The only way to know is to monitor and look at the prompts! This is where limits, truncation, summarization, and compression become very useful safeguards.
📈 Not monitoring token usage
Since context token windows are the most precious resource, not monitoring input & output token usage is one of the easiest ways to unknowingly introduce context rot. Token consumption should be monitored in aggregate and also across various dimensions so that you can spot trends and changes over time. Perhaps a new tool was introduced that has 100,000 token responses or the LLM gets caught in a doom loop where it’s repeating the same phrase over and over again. The only way to know is to monitor.
🗑️ Errors and junk context
Tools calls can fail for many reasons and their errors are often helpful to guide the LLM in how to succesfully make the next tool call. However, long, verbose errors can also pollute your context window. What’s even more common is “junk context” that might be returned from tool calls. Is a tool returning 10,000 log lines of the exact same content? Or is a RAG tool dumping volumes of completely unrelated documentation into the context window?
🎰 Few-shot example distribution
Few-shot examples are a great strategy for grounding LLMs in examples that represent your data. Keep in mind though that LLMs are probabilistic machines - the distribution of data they process will influence their output. Too many few-shot examples of one type, or a distribution of examples that doesn’t match your real-world data distribution, will lead the LLM in the wrong direction.
<instruction>
Classify the user's intent into one of these categories:
CHECK_BALANCE, MAKE_DEPOSIT, OPEN_ACCOUNT, OPEN_SUPPORT_TICKET
</instruction>
<examples>
User: I want to open a new checking account.
Intent: OPEN_ACCOUNT
User: How can I start a savings account with you?
Intent: OPEN_ACCOUNT
User: I need to deposit this check.
Intent: MAKE_DEPOSIT
User: I'd like to apply for a new account.
Intent: OPEN_ACCOUNT
</examples>
If your real-world distribution of intents is 75% account openings and 25% deposits this might make sense, but in general you should always balance out examples with the real-world distributions.
🧼 Preventing Context Rot
There are many small best practices that help to prevent context rot. They can be difficult to implement in one shot, but small steps towards broad adoption makes a big impact over time. These best practices include:
- Prompt instruction reviews - make sure the team is reading the prompt instructions together
- Prompt style guide - standardize any stylistic or formatting practices for the sake of consistency
- Prompt tracing - look at rendered prompts, the outputs, and identify egrigious issues
- Token analytics - gather analytics your token usage, tool usage, and any other dimensions that are important so you can see how tool, agent, and prompt changes affect your system across different dimensions.